

ABSTRACT
This paper describes the development and teaching of courses on Big Data Infrastructure Technologies for Data Analytics (BDIT4DA) as a component of the general Data Science curriculum. The authors utilized the EDISON Data Science Framework (EDSF) to build the course, specifically the Data Science Body of Knowledge (DS-BoK) related to the Data Science Engineering knowledge area group (KAG-DSENG). The paper provides an overview of cloud-based platforms and tools for Big Data Analytics and emphasizes the significance of incorporating practical work with clouds into the curriculum to prepare future graduates or specialists for the workplace. The paper also explores the relationship between the DSENG BoK and Big Data technologies and platforms, such as Hadoop-based applications and tools for data analytics, which should be promoted throughout the course activities including lectures, practical exercises, and self-study.
CCS Concepts
Computer systems organization -> Architectures -> Distributed architectures -> Cloud computing
Information systems -> Data management systems
Keywords
EDISON Data Science Framework (EDSF), Data Science Body of Knowledge (DS-BoK), Data Science Engineering, Big Data Infrastructure Technologies, Hadoop ecosystem, Cloud Computing.
1. INTRODUCTION
Modern Data Science and Business Analytics applications heavily rely on Big Data infrastructure technologies and tools that are mostly cloud-based and available on major cloud platforms. As a result, having knowledge and skills to work with modern Big Data platforms and tools is a requirement for Data Science practitioners to develop and operate data analytics applications effectively. Incorporating Big Data Infrastructure topics into the general Data Science curriculum can make it easier for graduates to integrate into the future workplace.
This paper effectively utilizes the EDISON Data Science Framework (EDSF), which was initially developed in the EDISON Project (2015-2017) and is currently maintained by the EDISON community [1, 2]. The EDSF provides a comprehensive framework for Data Science education, curriculum design, and competences management, as previously discussed by the authors [3, 4, 5]. Big Data Infrastructure Technologies (BDIT) are part of the Data Science Engineering Body of Knowledge (DSENG-BoK) defined in the EDSF, as well as the Model Curriculum (MC-DSENG), which is described in detail in this paper.
The focus of this paper is to define the Data Science Engineering Body of Knowledge and the Big Data Infrastructure Technologies for Data Analytics (BDIT4DA) course. The paper provides a brief overview of the Big Data infrastructure technologies and the existing cloud-based platforms and tools used for Big Data processing and data analytics, which are relevant to the BDIT4DA course. Large Information Stages and Devices for Information Examination in the Information Science Designing Educational Program The main focus is on cloud-based Big Data infrastructure and analytics solutions, particularly on understanding and utilizing the Apache Hadoop ecosystem as the primary Big Data platform, with its core functional components such as MapReduce, Spark, HBase, Hive, Pig, and supported programming languages Pig Latin and HiveQL.
Having knowledge and basic experience with major cloud service providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), as well as the Cloudera Hadoop Cluster or Hortonworks Data Platform, is crucial to developing the necessary knowledge and practical skills. These topics need to be included in both lecture courses and hands-on practice.
Large Information Stages and Devices for Information Examination in the Information Science Designing Educational Program The paper is organized as follows: Section 2 introduces the EDISON Data Science Framework (EDSF), Section 3 provides information about the Data Science Engineering Body of Knowledge (DSENG-BoK) and the DSENG Model Curriculum and its main components. Section 4 describes the Hadoop ecosystem used as the primary platform for Big Data applications, including its core components, other essential applications, and used programming and query languages. It also includes a brief overview of the Big Data platforms provided by major cloud providers. Section 5 describes an example of the course taught by the author in various educational environments and formats. Finally, the conclusion section 6 describes ongoing developments and activities in exchanging best practices in Data Science curriculum development and ongoing education
2. EDISON DATA SCIENCE FRAMEWORK (EDSF)
- The EDISON Data Science Framework (EDSF), which was developed by the EDISON Project, serves as a foundation for Data Science education and training, curriculum design, and competency management that can be tailored to specific organizational roles or individual needs. EDSF can also be used for professional certification and to ensure career transferability.
- The CF-DS, or Data Science Competence Framework, provides the overall basis for the entire framework. CF-DS includes the core competencies required for successful work as a Data Scientist in different work environments in industry and research, throughout the career path. The following are the core CF-DS competence and skills groups that have been identified: Data Science Analytics (DSDA), Data Science Engineering (DSENG), Large Information Stages and Devices for Information Examination in the Information Science Designing Educational Program Data Management and Governance (DSDM), Research Methods and Project Methods (DSRMP), and Domain Knowledge and Expertise (related to scientific domains).
- Data Science competencies must be supported by knowledge, which is primarily defined by education and training, and skills, which are defined by work experience. The CF-DS defines both types of skills, those related to basic competencies and professional experience, and those based on a wide range of practical skills, including using programming languages, development environments, and cloud-based platforms.
- The DS-BoK, or Data Science Body of Knowledge, defines the Knowledge Areas (KA) required for building Data Science curricula to support the identified Data Science competencies. DS-BoK is organized by Knowledge Area Groups (KAG) that correspond to the CF-DS competence groups. DS-BoK is based on the ACM/IEEE Classification Computer Science (CCS2012), incorporates best practices in defining domain-specific BoK’s, and provides reference to existing related BoK’s. It also includes proposed new KA to incorporate new technologies and scientific subjects required for consistent Data Science education and training.
- The MC-DS, or Data Science Model Curriculum, is built based on DS-BoK and linked to CF-DS, where Learning Outcomes are defined based on CF-DS competencies (specifically skills type A), and Learning Units are mapped to Knowledge Units in DS-BoK. Three mastery (or proficiency) levels are defined for each Learning Outcome to allow for flexible curricula development and profiling for different Data Science professional profiles. Practical curriculum should be supported by corresponding educational environment for hands-on labs and educational projects development.
- The formal definition of DS-BoK and MC-DS creates a foundation for Data Science educational and training program compatibility and, consequently, Data Science-related competencies and skills transferability.
3. DATA SCIENCE ENGINEERING BOK AND MODEL CURRICULUM

DSENG Model Curriculum Components
Large Information Stages and Devices for Information Examination in the Information Science Designing Educational Program The Data Science Engineering Knowledge Group focuses on the use of engineering principles to design, develop, and implement new instruments and applications for data collection, analysis, and management. It covers a variety of Knowledge Areas, such as software and infrastructure engineering, the manipulation and analysis of complex data, structured and unstructured data, and cloud-based data storage and management.
Data Science Engineering involves software development, infrastructure operations, and algorithm design to support Big Data and Data Science applications both in and outside of the cloud. Commonly defined Knowledge Areas in this group include Big Data infrastructure and technologies, infrastructure and platforms for Data Science applications, Cloud Computing technologies for Big Data and Data Analytics, Data and Applications security, accountability, certification, and compliance, Big Data systems organization and engineering, Data Science application design, and Information Systems to support data-driven decision making.
The DS-BoK maps the Data Science Engineering Knowledge Areas to existing classifications and BoKs, such as ACM Computer Science BoK, Software Engineering BoK, and related scientific subjects from CCS2012. This provides a basis for creating compatible and transferable educational and training programs in Data Science Engineering.
3.2 DSENG/BDIT – Big Data infrastructure technologies course content
- Big Data infrastructures and technologies are critical components of Data Science applications. They present unique challenges due to the high volume, velocity, and variety of data that must be stored and transformed. The curriculum for Data Science Engineering (DSENG) must include topics such as Data Lakes and SQL/NoSQL databases to address these challenges.
- The deployment of Data Science applications is often linked to popular platforms like Hadoop or Spark, which can be hosted either on private or public clouds. In addition to the application workflow, a data processing pipeline must also consider data ingestion and storage for various data types and sources. Data Scientists must have a fundamental understanding of data and application security aspects to ensure proper planning and execution of data-driven processing in their organization. The DSENG curriculum should cover the most important security aspects, including accountability, compliance, and certification.
- Data Management and Governance (DMG) is a separate knowledge area (KAG4-DSDM) that should be included in the DSENG courses. A brief overview of DMG’s common practices, including the FAIR data principles, should also be incorporated into the BDIT curriculum. The FAIR principles, which emphasize that data should be Findable, Accessible, Interoperable, and Reusable, are increasingly being adopted by the research community and recognized by industry. Data Stewardship is a DMG application domain that combines general and subject domain data management to ensure that FAIR principles are incorporated into the organization’s practice..
4. PLATFORMS FOR BIG DATA PROCESSING AND ANALYTICS
In this section, we’ll talk about the different platforms that can be utilized for teaching the BDIT4DA course, as well as other courses within the Data Science Engineering curriculum that require the processing of Big Data. One of the most popular platforms for this purpose is the Hadoop Ecosystem, which consists of several main components that offer various functionalities. In addition to this, we’ll also provide information on cloud-based Big Data infrastructure and analytics platforms offered by major cloud service providers..
4.1 Essential Hadoop Ecosystem Components
Hadoop is a widely used platform for processing Big Data. It comprises various components and applications developed by the Apache Open Source Software community, offering comprehensive functionality to support all stages of the data processing workflow or pipeline. In the BDIT4DA course, it is crucial to provide a basic understanding and practical experience with the Hadoop tools and applications, which is accomplished through practical activities and assignments. Figure 1 depicts the Hadoop main components and other popular data processing applications [12, 13].
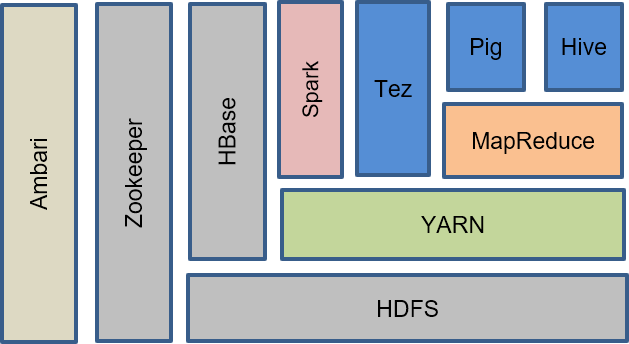
Figure 1. Main components of the Hadoop ecosystem
The Hadoop ecosystem is composed of various applications and tools developed by the Apache Open Source Software community. The main components of Hadoop are HDFS, MapReduce, YARN, and Tez. HDFS is designed for large-scale storage and processing of data on commodity hardware, while MapReduce is a YARN-based system for parallel processing of large data sets. YARN is a framework for job scheduling and cluster resource management, while Tez is a powerful and flexible engine that executes an arbitrary DAG of tasks to process data for both batch and interactive use-cases.
Other Hadoop-related projects at Apache provide a rich set of functionalities for data processing throughout the data lifecycle. Hive is a data warehouse system that provides data aggregation and querying, while Pig is a high-level data-flow language and execution framework for parallel computation. HBase is a distributed column-oriented database that supports structured data storage for large tables. Spark is a fast and general compute engine for Hadoop data, providing a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation. Mahout is a scalable machine learning and data mining library, while Solr is an open-source enterprise search platform that uses Lucene as an indexing and search engine. Oozie is a server-based workflow scheduling system to manage Hadoop jobs, while Ambari is a web-based tool for provisioning, managing, and monitoring YARN jobs and Apache Hadoop clusters. Hue is a user graphical interface that provides full functionality for programming Hadoop applications, including dashboard, data upload/download, and visualization.
4.2 Hadoop Programming Languages
To effectively integrate the Hadoop platform and its tools into research and business applications, it is necessary to introduce multiple Hadoop programming options. The Hadoop platform is primarily programmed in Java, but many applications also support Scala. Additionally, there is support for Hadoop API calls from popular programming and data analytics tools such as R, Python, C, and .NET. Hadoop also has specific query languages for working with HBase, Hive, and Pig.
Hive Query Language (HiveQL or HQL) is a higher-level data processing language used for Data Warehousing applications in Hadoop. It is a variant of SQL, and tables are stored on HDFS as flat files. HiveQL enables large-data processing and compiles down to Hadoop jobs.
Pig Latin is a scripting language used for describing data processing flows in large-scale data processing systems. It is similar to HiveQL in that it has query commands, but it also includes additional flow control commands. Like HiveQL, Pig Latin compiles down to Hadoop jobs and relies on MapReduce or Tez for execution.
4.3 Cloud-based Big Data Platforms
The major cloud platforms such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer a wide range of Big Data services and applications. For example, AWS offers Elastic MapReduce (EMR), a hosted Hadoop platform for Data Analytics, Amazon Kinesis for real-time processing of streaming big data, Amazon DynamoDB for scalable NoSQL data stores, Amazon Aurora for scalable relational database, and Amazon Redshift for fully-managed petabyte-scale data warehouse. Similarly, Microsoft Azure provides a well-integrated Big Data and Analytics stack that includes HDInsight based on Hortonworks Hadoop platform, Data Lake Storage and Analytics, CosmosDB for multi-format NoSQL database, and other services. Google Cloud provides easy-to-configure Big Data services such as BigQuery for column-based NoSQL database and Google Spanner for Big SQL database, along with a Machine Learning stack with well-defined APIs that support the entire data analytics process.

In an example course for Big Data Infrastructure and Technologies for Data Analytics, students may learn about the Hadoop ecosystem, programming options, and the use of cloud platforms for Big Data processing. The course may cover topics such as HDFS, MapReduce, YARN, Tez, HiveQL, Pig Latin, and Spark, and how these tools can be used to process and analyze large data sets. Students may also gain practical experience in using AWS, Microsoft Azure, or Google Cloud to build and deploy Big Data applications. Overall, the course aims to provide students with the skills and knowledge to effectively work with Big Data and prepare them for careers in data science and analytics. The BDIT4DA course comprises of lectures, hands-on labs, projects, and engaging activities like literature study and seminars. It can be tailored to suit various academic or training programs. To provide students with exposure to real-world practices and external experts, the course should also feature a few guest lectures.
4.4 BDIT4DA Lectures
The BDIT4DA course structure should be adaptable to different academic and training programs. It should include lectures, practice/hands-on labs, projects, and engaging activities such as literature study and seminars. Additionally, guest lectures from external experts can expose students to real-world practices.
The lectures should provide a foundation for understanding the BDIT4DA technology domain, available platforms, tools, and link other course activities. However, the form and technical level of lectures should be adjusted according to the incumbent program to cater to different audiences, such as Computer Science and MBA programs. The selection of practical assignments and used tools and programming environments should also be adjusted accordingly.
An example set of lectures developed and taught by the authors includes:
Lecture 1: Cloud Computing foundation and economics, covering cloud service models, resources, and operation, outsourcing enterprise IT infrastructure to cloud, cloud use cases and scenarios, and cloud economics and pricing models.
Lecture 2: Big Data architecture framework and cloud-based Big Data services, providing an overview of major cloud-based Big Data platforms such as AWS, Microsoft Azure, and Google Cloud Platform (GCP), as well as the MapReduce scalable computation model and the Hadoop ecosystem and components.
Lecture 3: Hadoop platform for Big Data analytics, covering Hadoop ecosystem components such as HDFS, HBase, MapReduce, YARN, Pig, Hive, Kafka, and others.
Lecture 4: SQL and NoSQL Databases, providing an overview of SQL basics, popular RDBMS, NoSQL databases types, column-based databases, and modern large-scale databases such as AWS Aurora, Azure CosmosDB, and Google Spanner.
Lecture 5: Data Streams and Streaming Analytics, covering data streams and stream analytics, Spark architecture and components, popular Spark platforms such as DataBricks, Spark programming and tools, and SparkML library for Machine Learning.
Lecture 6: Data Management and Stewardship/Governance, discussing enterprise Big Data architecture and large-scale data management, data governance and data management, and FAIR principles in data management.
Lecture 7: Big Data Security and Compliance, addressing Big Data security challenges, data protection, cloud security models, cloud compliance standards, and cloud provider services assessment, including the CSA Consensus Assessment Initiative Questionnaire (CAIQ) and PCI DSS cloud security compliance.
4.5 Practice and project development
To ensure practical learning, students must work with the main Hadoop applications and programming simple data processing tasks. Various Hadoop platforms can be used for running practical assignments, such as Cloudera Hadoop Cluster or Hortonworks Data Platform, or cloud-based platforms like AWS Elastic MapReduce or Azure HDInsight. Students may also be recommended to install a personal single host Hadoop cluster using either Cloudera Starter edition or Hortonworks Sandbox.
Here are some example topics for practice and hands-on assignments:
- Getting started with the selected cloud platform: Students can learn how to use cloud services such as Amazon Web Services (AWS) EC2 and S3, and deploy virtual machine instances.
- Understanding MapReduce and Pregel algorithms: Students can run a Wordcount example using the MapReduce algorithm, either manually or with Java MapReduce library.
- Getting started with the selected Hadoop platform: Students can learn how to use the command line and visual graphical interface (e.g. Hue), and how to upload and download data. They can also run simple Java MapReduce tasks.
- Working with Pig: Students can use simple Pig Latin scripts and tasks, and develop a Pig script for programming Big Data workflows.
- Working with Hive: Students can run simple Hive scripts for querying Hive databases, import external SQL databases into Hive, and develop Hive scripts for processing large datasets.
- Streaming data processing with Spark, Kafka, and Storm: Students can use simple tasks to program Spark jobs and Kafka message processing. They can also use Databricks platforms, which provide good tutorial websites.
- Creating dashboards and data visualisation: Students can use tools available from the selected Hadoop platform to visualise data, particularly using results from Practice 5 or 6, where a dashboard is necessary.
- Cloud compliance practicum: Students can use Consensus Assessment Initiative Questionnaire (CAIQ) tools to understand complex compliance issues for applications run on the cloud.
- These practical assignments will help students gain hands-on experience with the various tools and platforms used in Big Data and Information Technology for Data Analytics.
5. CONCLUSION
This paper outlines an approach to teaching Big Data Infrastructure Technologies for Data Analytics based on the EDISON Data Science Framework. This framework is widely used in universities, professional training organizations, and certification organizations, and is continually evolving based on feedback. The approach is informed by the author’s experience in teaching cloud computing technologies, which provide a necessary foundation for Big Data technologies.
In order to prepare graduates and trainees for the rapidly evolving field of Data Science, academic education and professional training should be supplemented with courses that develop 21st century skills and specific workplace skills. Research Data Management and Stewardship, adopting FAIR data principles, is considered a general skill for data workers and is part of the FAIRsFAIR project.
The EDISON community coordinates the maintenance and development of the EDSF, as well as the collection of best practices in Data Science education and training. This effort is supported by national and EU projects, as well as the Research Data Alliance (RDA) Large Information Stages and Devices for Information Examination in the Information Science Designing Educational Program Interest Group on Education and Training on Handling Research Data. Participation and contribution to both the IG-ETHRD and EDSF Community Initiative is open and free.
6. REFERENCES
- EDISON Community wiki. [online] https://github.com/ EDISONcommunity/EDSF/wiki/EDSFhome
- EDISON Data Science Framework (EDSF). [online]
- Yuri Demchenko, Luca Comminiello, Gianluca Reali, Designing Customisable Data Science Curriculum using Ontology for Science and Body of Knowledge, 2019 International Conference on Big Data and Education (ICBDE2019), March 30 – April 1, 2019, London, United Kingdom, ISBN978-1-4503-6186-6/19/03
- Demchenko, Yuri, et all, EDISON Data Science Framework: A Foundation for Building Data Science Profession For Research and Industry, Proc. The 8th IEEE International Conference and Workshops on Cloud Computing Technology and Science (CloudCom2016), 12-15 Dec 2016, Luxembourg.
- Yuri Demchenko, Adam Belloum, Cees de Laat, Charles Loomis, Tomasz Wiktorski, Erwin Spekschoor, Customisable Data Science Educational Environment: From Competences Management and Curriculum Design to Virtual Labs On-Demand, Proc. 4th IEEE STC CC Workshop on Curricula and Teaching Methods in Cloud Computing, Big Data, and Data Science (DTW2017), part of The 9th IEEE International Conference and Workshops on Cloud Computing Technology and Science (CloudCom2017), 11- 14 Dec 2017, Hong
- The 2012 ACM Computing Classification System [online] http://www.acm.org/about/class/class/2012
- ACM and IEEE Computer Science Curricula 2013 (CS2013) [online] http://dx.doi.org/10.1145/2534860
- Software Engineering Body of Knowledge (SWEBOK) [online] https://computer.org/web/swebok/v3
- Data Management Body of Knowledge (DM-BoK) by Data Management Association International (DAMAI) [online] http://www.dama.org/sites/default/files/download/DAMA-
DMBOK2-Framework-V2-20140317-FINAL.pdf
- Data Maturity Model (DMM), CMMI Institute, 2018 [online] https://cmminstitute.com/data-management-maturity
- Barend Mons, et al, The FAIR Guiding Principles for scientific data management and stewardship [online] https://www.com/articles/sdata201618
- Apache Hadoop [online] https://hadoop.apache.org/
- Hadoop Ecosystem and Their Components – A Complete Tutorial [online] https://data-flair.training/blogs/hadoop- ecosystem-components/
- Apache Hive Tutorial [online] https://cwiki.apache.org/confluence/display/Hive/Tutorial
- Apache Pig Tutorial [online] https://data- flair.training/blogs/hadoop-pig-tutorial/
- Amazon Web Services (AWS) [online] https://aws.amazon.com/
- Microsoft Azure [online] https://docs.microsoft.com/en- us/azure/architecture/data-guide/
- Google Cloud Platform [online] https://cloud.google.com/
- Cloudera Hadoop Cluster (CDH) [online] https://www.com/documentation/other/reference- architecture.html
- Hortonworks Data Platform [online] https://hortonworks.com/products/data-platforms/hdp/
- Demchenko, Yuri, David Bernstein, Adam Belloum, Ana Oprescu, Tomasz W. Wlodarczyk, Cees de Laat, New Instructional Models for Building Effective Curricula on Cloud Computing Technologies and Engineering. Proc. The 5th IEEE International Conference and Workshops on Cloud Computing Technology and Science (CloudCom2013), 2-5 December 2013, Bristol,
- FAIRsFAIR Project [online] https://www.eu/
- Research Data Alliance (RDA) Education and Training on Handling of Research Data interest Group (IG-ETHRD) [online] https://rd-alliance.org/groups/education-and- training-handling-research-data.html